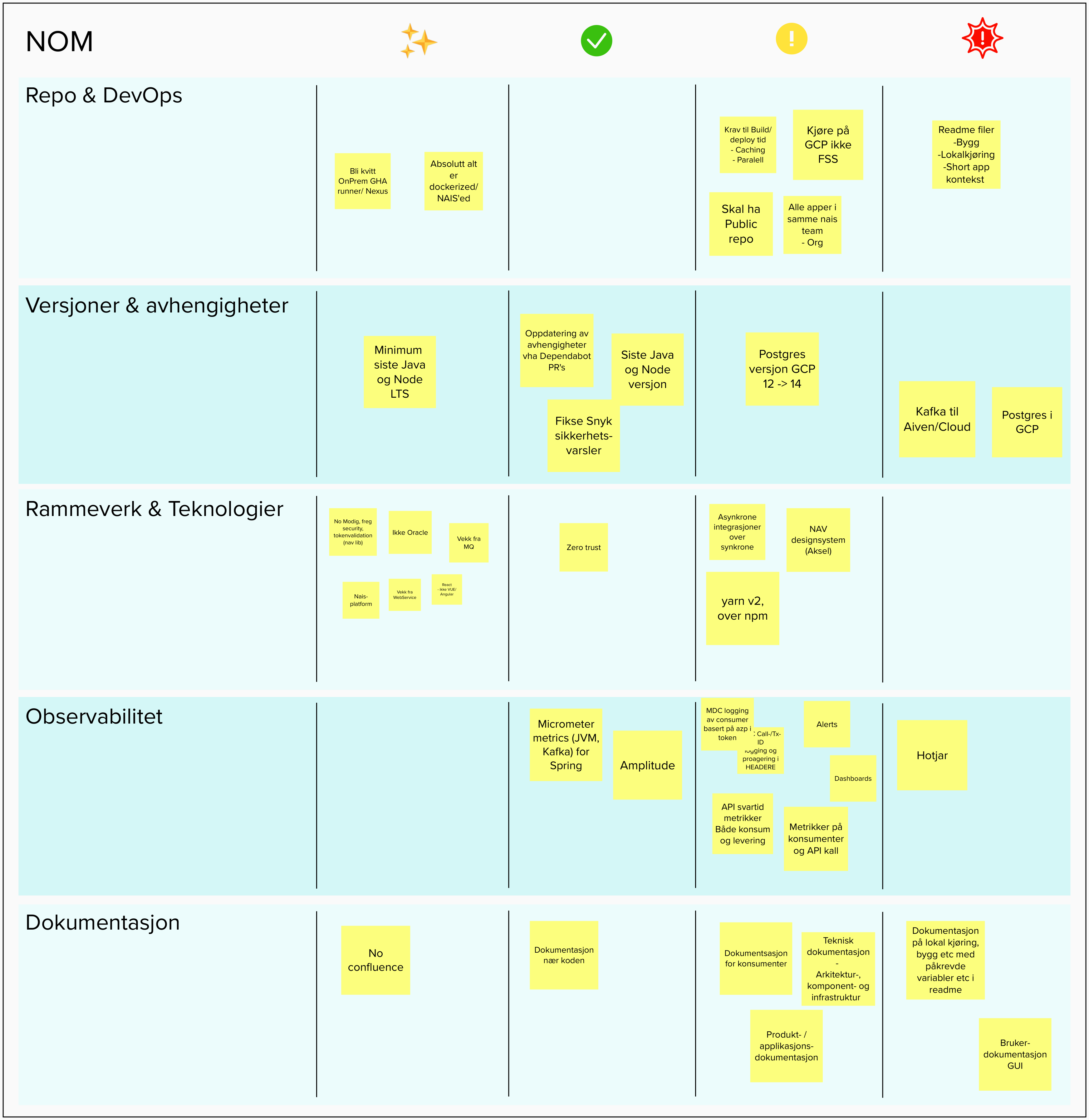
1. Dokumentasjon
Ligger under monorepo nom/docs/src/main/asciidoc.
Det finnes en plugin til intellij som gjør dette enklere (Asciidoc plugin).
En nyttig guide: Vogella Asciidoctor.
Og: Powerman
2. Teststrategi
I NOM jobber vi mot automatiserte tester så langt det går. Dette fordi manuell testing er kjedelig, tidkrevende og har høy risiko for feil.
Her har vi da hovedfokus på integrasjons testing. Som er tester for å validere vårt eget system i et mer isolert miljø.
Vårt mål med testene våre er: - Selvtillit for at koden vår fungerer. - Gi oss rask tilbakemelding som er å stole på. - Gjøre vedlikehold letter ved å vite at vi ikke ødelegger eksistende funksjonalitet.
Som også understøtter vår praksis med trunk based development.
Har satt opp en base-klasse slik at spring -context kun kjøres opp én gang for alle testene.
Rammeverk: - Springboot test rammeverk - Wiremock (stubbing) - Docker (Containere for database)
3. Arbeidsmetodikk
3.1. QA / Parprogrammering
I NOM praktiserer vi QA / Parprogrammering på alle endringer av større betydning som skjer i prosjektet. På en QA trenger man derfor godkjennelse av minst 1 annet team medlem på en pullrequest før endringene går i master.
Ved parprogrammering har man vært to som har skrevet koden og dermed fått en implisitt QA av koden underveis. Denne koden kan derfor pushes rett til produksjon.
4. Monorepo
Monorepo gjør oss i stand til å holde endringer synkronisert på tvers av applikasjonene NOM består av.
applikajsoner som inngår i monorepoet:
-
ressurs
-
api
-
proxy
-
ui
Repoet ligger på github.
5. Deployment og Branching
Vi følger prinsippet om trunk based development så langt det går, men bruker short lived branches når vi må prøve mer eksperimentelle endringer.
Applikasjonene NOM består av deployes som docker containere som kjører på NAV sin NAIS plattform, og det er satt opp CI (github actions) slik at applikasjonene deployes på nytt til miljø ved git push.
Trigging av CI per applikasjon avhenger av om den faktisk ble berørt av en endring i kildekoden. F:eks vil man kunne gjøre en endring på frontend, pushe disse endringene til monorepo, og se at kun CI relevant for frontend-applikasjonen kjører.
7. Applikasjoner
7.1. State of the union
Delt i oversikten på https://navikt.github.io/team-org/#_state_of_the_union
7.2. NOM-Api
Integrasjonspunkt for konsumenter utenfor NOM, og NOM-Ui.
Eksponerer GraphQL for å hente informasjon fra NOM.
7.3. NOM-PROXY
Står for kommunkasjonen mellom NOM og onprem services som datavarehus og AD. DVH eksponerer noen endepunkter via tdv der hvor de gir oss opplysninger rundt enheter og ressurser. Disse opplysningene er igjen hentet fra eksterne kilder som Agresso, Norg, +. På sikt, er det tenkt at NOM blir master for en del av disse opplysningene og at DVH får det fra oss i stede for alle disse andre spredte kildene.
Endepunktene NOM proxy eksponerer blir konsumert (polling) av enten NOM-Ressurser eller NOM-API, der førstnevnte bruker et offset basert endepunkt, mens sistnevnte bruker snapshots og gjør en diff-jobb selv for å trekke ut hvilke
Informasjon hentes fra DVH via feeds som baserer seg på et offset, f.eks 10101920, der hvor man etterspør alle rader etter dette. Dataen blir så lagret på Kafka for at vi kan benytte i andre applikasjoner.
Offset blir lagret sammen med dataen, slik at ved oppstart av applikasjonen så vil man laste inn alle records og beholde det siste offsettet innenfor typen. F.eks:
Key: Enhet-9238823, Value: { "offset": 9238823..... }
Key: Enhet-9238824, Value: { "offset": 9238824..... }
Key: Ressurs-102939, Value: { "offset": 102939..... }Spiller man av Kafka topicen fra begynnelsen og opp til topp, så sitter man igjen med offset for enhet=9238824 og ressurs=102939.
Data lagres på Kafka topicen: aapen-nom-dvhSource-v1.
7.4. NOM-Ui
Frackend (backend for frontend) for ui delen av NOM.
Holder på sessjoner for bruker og proxyer kall videre til eventuelle nedstrøms-tjenester.
Proxy benyttes for å støtte accessPolicies mellom applikasjoner, pluss at man må bytte ut token til et on-behalf-of token som har audience den appen man kontakter.
7.5. NAV ident komponent
7.5.1. Hva er NAV ident komponent (NIK)?
NAV ident komponent (heretter forkortet "NIK") er en liten komponent som står for all opprettelse av NAV-identer i NAV. NAV-ident er en unik nøkkel for hver person (og andre som skal opptre som en person - f.eks. roboter) som skal utføre en oppgave i NAV. Komponenten er master for NAV-identer, og deres knytning til fnr/dnr og evt. andre nøkler brukt internt i NAV.
7.5.2. Hvorfor trengs denne komponenten?
NAV-identer må være unike. Når en sentral komponent står for dette, vil flere konsumenter kunne bestille identer uten konflikt.
Generering og bokholderi på nav-identer blir en veldig stabil type funksjonalitet som ikke vil endre seg særlig over tid.
Dersom NIK hører mer hjemme i IDM-sfæren, så er det enklere å flytte komponenten dit dersom den er adskilt fra øvrige HR-systemer i teamet.
7.5.3. Hvilke data skal NIK inneholde?
NIK skal være smal og holde på NAV-ident, dets knyting til fødselsnr/d-nr/annen nøkkel, samt metadata. Løsningen vil også holde på historiske personid knyttet til NAV-identen, samt alle historiske NAV-identer.
Utledes via eventsourcing?
{
navident: <string (a123456)>
personid: <string (fnr/d-nr/annen nøkkel)> - den aktive personid'en for navidenten
allePersonider: [ string (fnr/d-nr/annen nøkkel) ]
identType: <ROBOT | STANDARD | VIKAFOSSEN | UTENLANDSK_KONSULENT>
}Foreslått format på annen nøkkel: <XXX999> Navn på "annen nøkkel" bør gis av Sikkerhetsseksjonen i og med at det er de som utdeler denne.
Eventsourcing metadata rundt bestillinger (opprett, slett)
{
event: "OPPRETT" | "SLETT"
eventTS: DateTime (Timestamp for selve eventen)
bestiller: Nav-ident/system
payload: {
navident: string (a123456)
personid: string (fnr/d-nr/annen nøkkel)
identType: ROBOT | STANDARD | VIKAFOSSEN | UTENLANDSK_KONSULENT
}
}7.5.4. API
Hvilke spørsmål og forespørsler forventer vi at konsumenter vil ha?
-
Hvilken navident har dette personid?
-
Hvilket personid har denne navidenten?
-
Har denne navidenten flere tilknyttede person-id?
-
Gi meg nav-ident for personId (enten det gamle eller opprett nytt på stedet)
-
Gi meg navident for personId, med selvbestemt prefix bokstav (enten det gamle eller opprett nytt på stedet)
-
Er denne identen en (robot | utenlandskkonsulent | vikafossen | øvrig ansatte/konsulenter) ?
-
Gi meg alle navidenter i en gitt kategori (robot | utenlandskkonsulent | vikafossen | vanlig-ansatt)
REST
Bestilling blir på rest. En bestilling vil gi en ny eller eksisterende navident tilbake basert på om personidenten finnes ifra før. Bestillingen vil knyttes til pålogget nav-ident via aad-obo
Opprette eller reaktivere en navident
Request: POST /personid
{
personid: string påkrevd (f-nr, d-nr, annen nøkkel)
identType: string <ROBOT | STANDARD | VIKAFOSSEN | UTENLANDSK_KONSULENT> - Default STANDARD
}Respons:
200 OK hvis den eksisterer ifra før
201 CREATED hvis den blir nyopprettet
body:
{
navident: <ny eller eksisterende navident for angitt personid>
}
201 CREATED Angitt personid for ordinær ident finnes ikke i PDL, men vi genererer allikevel navident
body:
{
navident: <ny navident generert>
feilmelding: "Angitt personid for STANDARD ident finnes ikke ifra før, og finnes heller ikke i PDL eller PDL oppslag feilet"
}
200 OK Angitt personid for ordinær ident finnes ikke i PDL, men vi vi fant den som tidligere navident
body:
{
navident: <ny navident generert>
feilmelding: "Angitt personid for STANDARD ident finnes ifra før, men finnes ikke i PDL eller PDL oppslag feilet"
}
500 Internal Server Error
body:
{
feilmelding: <Feilårsak>
}REST tjenesten utfører følgende handlinger: - Lager 'bestillings' event på kafka (egen request/forespørsel topic?) som en 'need' melding
{
personid: string påkrevd (f-nr, d-nr, annen nøkkel)
identType: string <ROBOT | STANDARD | VIKAFOSSEN | UTENLANDSK_KONSULENT>
}-
'Oppslag' - konsument slår opp om det finnes eksisterende navident og legger til dette i 'need' medlingen over
{
...<tidligere data i need melding>...
eksisterendeIdent: { <Tom hvis den ikke eksisterer>
navident: <eksisterende navident>
}
}-
'PDL' - konsument sjekker mot PDL for å finne personident hvis identtypen er STANDARD. Populerer eksisterende informasjon om personid i 'need' meldingen over
{
...<tidligere data i need melding>...
pdl: {
personid: <string (fnr/d-nr)> - den gjeldende id'en i PDL
allePersonider: [ <Tom hvis den ikke eksisterer i PDL>
personid: <string (fnr/d-nr)>
]
}
}-
'NAV ident generator' - konsument trår til hvis need meldingen har fått feltet 'eksisterendeIdent' men den er tom. Da lager den ny ident og legger det til i need meldingen:
{
...<tidligere data i need melding>...
nyNavident: <Ny generert navident>
}-
'Respons' konsument kan returnere svar så fort den enten har funnet en eksisterende ident. Eller need meldingen har fått 'ny navident' og PDL ident finnes hvis det er ORDINÆR ident. Respons konsumenten kan legge til sin fulle respons til i 'need' meldingen.
{
...<tidligere data i need melding>...
respons: {
responseCode: <HTTP response code>
responsBody: {
<Som returert i REST meldingen>
}
}
}-
'EventSourceProducerKonsument' - Må lage en event melding på eventsource køen, og også persistere denne i base. Event hendelsen vil være enten en 'OPPRETT'. Selv om det er en ifra før, for å oppdatere eksisterende info.
Kafka
NB. Kafka egner seg ikke for persistering.
Ha en topic for lesing? utledet stream for "nå-bildet"
Eventsourcing
Event source navIdent på topic nav-ident.
navident brukes som meldingsnøkkel
Lage en Kafka stream med sink til PostgreSQL for backup. Egen rutine for recovery av eventsource må lages
| Eventsource som beskrevet nå vil bestå av en eller flere OPPRETT meldinger for en navident. Og en teknisk SLETT melding. Kanskje splitte OPPRETT i to og lage OPPRETT og OPPDATER. Jira https://jira.adeo.no/browse/ORG-596 |
Persistering
Database for backup av kø og ACID transaksjon for å unngå dobbelt-booking Trenger vi det? Er det et reelt problem? Sekvens = vanlig databasesekvens
Identgenereringslogikk
navident = ( Første bokstav i etternavn → bokstav) + sekvensnr
Sekvensen er unik i seg selv, og brukes i dag bl.a. i UNIT4 som ressursnr.
Corner-cases
Roboter - Hvem er ansvarlig for roboten? Kan man bruke org-tilknytning for dette? - Hvis roboten ikke har org-tilknytning, skal det settes opp en manuelt ansvarlig?
Kort-tids konsulenter fortrinnsvis fra utlandet, uten personnr eller d-nummer. Administreres av Sikkerhetsseksjonen.
Vikafossen ansatte: Administreres av Sikkerhetsseksjonen. NIK oppretter kun NAV-ident, og skal ikke ha nok info til å identifisere den fysiske personen.
Riksrevisjonen: Trenger navident for å kunne lese
Helfo: jobber i en del av navs applikasjoner.
En del andre eksterne virksomheter som: Skatt, NSM, Helsetilsynet m.fl.
Hypoteser
-
utenlandskonsulenter trenger ikke være i lønnssystemet for å få betalt
-
(?) Roboter har fast prefix-bokstav i sin nav-ident
-
Robot knyttes til en org.enhet i NOM. Leder for org.enheten er da ansvarlig for roboten.
-
vikafossen har prefix-bokstav "s", av fiktivt etteravn "Skjult"
-
egentlig 3 stykker fiktiv/skjult/ukjent etc
-
anonyme nav-identer har prefix-bokstav "a", av fiktivt etternavn "Anonym"
-
Verifisering av identitet:
-
identiteten er verifisert FØR den når NIK
-
NIK er slave av NOM når det kommer til navn
-
Kan ikke endre en bestilling tilbake i tid for audit-formål
-
NIK stoler på at bestillingene den får er verifisert av bestiller (f.eks nom/remedy) mtp gyldig personident
-
IDA-identer starter alltid med Z som bokstav-prefix
-
Abonnerer ikke på endringsmeldinger fra PDL.
-
Gjør kall til PDL ved hvert oppslag i NIK slik at man får hentet evt. nye fnr på personen.
-
NIK skal ikke si noe om status aktiv/inaktiv eller perioder knyttet til dette på identer. NIK holder bare mapping av nav-identer og fnr/dnr/annen nøkkel. Aktiv/inaktiv er kontekstavhengig, f.eks. om du var ansatt eller ikke, eller når du hadde tilganger eller ikke, og den informasjonen bor i andre løsninger (f.eks. IGA for tilganger og NOM for ansettelse). Avklart med Team IDM.
Åpne punkter
-
IDAs Z-identer? Z-identene er på egen nummerserie, og skal ikke blandes med NIK sin nummerserie. Bør NIK ha en preprod-instans med bare synt-testdata, som er koblet til Dolly, slik at fagsystemer og andre kan bruke NOM-NIK med utelukkende syntetiske data.
-
I dialog med Trond i Sikkerhetsseksjonen (10.08.2022) kom det frem et behov for å kunne hente ut alle identer som er knyttet til tilsynsmyndigheter (Riksrevisjon, helsemyndigheter m.fl.). Behovet er knyttet til at når noen ber om logginnsyn, så skal NAV ikke levere ut eventuelle oppslag tilsynsmyndighetene har gjort, og da må det filtreres bort. Ved å ha støtte for at typen ident sier noe om at det er tilsynsmyndiget, ideelt på hvilken tilsynsmyndighet, så vil dette kunne gjøres enkelt utenfor NIK. Må få en komplett liste over hvem disse tilsynsmyndighetene er.
-
Vikafossen-identer skal ikke være like synlig som øvrige identer melder Trond i Sikkerhetsseksjonen. Må gå opp med flere hvilke LES-regler som stilles for Vikafossen, og evt. andre grupper identer.
-
Trond antar også at roboter bør eies av enhetene som ønsker å ha de, og ikke Sikkerhetsseksjonen. I dag er det ikke veldig synlig for enhetsledere hvilke roboter som operer under dem, nå er det mange av disse ledere som ikke har kontroll over egne enheter.
7.6. Lokal utvikling mot miljø
Man må være tilkoblet naisdevice for å kunne kjøre lokalutvikling mot miljø.
-
NOM-UI frackend må startes først:
-
Kopier teksten i filen
apps/ui/src/main/resources/application-local-template.yamltil en ny filapplication-local.yamli samme mappe -
Sett inn oppdaterte AAD credentials i
application-local.yaml. Hentes i clusteret, gjerne med et script. -
Start ui lokalt, med profiles
local,dev -
Hvis UI f.eks kjører på port 8080, gå til https://localhost:8080/login og logg inn med trygdeetaten bruker, enten din egen eller bruker generert i https://ida.intern.nav.no
-
UI Frackend vil nå gjøre API kall direkte mot miljø via naisdevice.
-
-
Deretter kan react-dev server kjøres opp
-
kjør
npm installi apps/ui/src/main/webapp/ -
kjør
npm run starti samme mappe -
api kall gjort mot react dev server proxies videre til frackend
-
Se fulle navn i hva som benyttes i vanlig property filen til nom-ui (altså som kommer fra Kubernetes i miljø).
Aktiver så profile local i IntelliJ og kjør eventuelt port-forward (se annet kapittel for kommando, søk i dokumentet) for å få tiltang til ressurser i dev.
Hvis man går mot miljø, husk å oppdatere base-paths for tjenestene man benyttes til å matche hva man har port-forwarda til.
F.eks, api.base-base: localhost:8081.
7.6.1. How to run locally
-
Spin up docker-containers with
docker-compose up -dlocated in project-root. -
In IntelliJ, go to Run/Debug Configuration and assign
localas your Active profile.
En midlertidig feil med docker-oppsettet er at kafka topic på en ny container ikke opprettes før første melding på topicet er sendt.
7.6.2. Hvordan benytte pgAdmin lokalt
pgAdmin er satt opp lokalt på adressen http://localhost:8089/ med bruker/passord = user@domain.com/password.
For å nå en lokal nom database velg 'Create server' og gi den ett navn på 'General' tabben.
På 'Connection' tabben sett opp følgende:
Host name: enhet-db/ressurs-db/skjermet-db (velg en)
port: 5432/5433/5434 (henholdsvis)
Maintenance database: postgres-enheter/postgres-ressurs/postgres-skjermet (henholdsvis)
Username: postgres
Password: passwordKryss gjerne av for lagre passord.
På 'Advanced' tabben må 'Host Address' være ip adressen til maskinen din. Eksempelvis 192.168.39.139. Altså ip adressen til docker host. Dette kan ikke være localhost referanse, for det vil bare peke på ip adressen som pgAdmin docker container har fått.
pgAdmin har fått en docker volume for config oppsett slik at denne konfigurasjonen persisteres mellom hvar gang men kjører opp lokalmiljøet.
7.6.3. Bygg og test på MAC med Colima og uten Docker Client
org.testcontainers klarer ikke ut av boksen å benytte Colima docker.
Lag filen: ~/.testcontainers.properties
docker.host=unix\:///Users/g155033/.colima/docker.sock
docker.tls.verify=0host referansen finner du med:
docker context ls
Eks:
❯ docker context ls
NAME DESCRIPTION DOCKER ENDPOINT KUBERNETES ENDPOINT ORCHESTRATOR
colima * colima unix:///Users/g155033/.colima/docker.sock
default Current DOCKER_HOST based configuration unix:///var/run/docker.sock https://apiserver.prod-fss.nais.io (org) swarmTil slutt må Ryuk skrus av siden den vil ha elevated rettigheter for å rydde bort testcontainere. Sett følgende environment variable:
TESTCONTAINERS_RYUK_DISABLED=true
8. Konsumenter
8.1. Konsumenter av NOM
| Konsument | Oppetids-krav | Volum/responstid? | Beskrivelse av data og bruken | Konsekvens av nedetid, evt. andre kommentarer |
|---|---|---|---|---|
Teamkatalogen |
Ikke kritisk |
Ikke kritisk |
Konsumerer orgEnhetsdata over graphQL |
Ikke kritisk konsument, tåler nedetid på timer. Påvirker ikke innbygger. |
Fullmaktsregister |
24/7? |
? |
TODO |
Understøtter denne en tjeneste på nav.no?? |
Remedy Identrutina |
Arbeidstid |
Ikke kritisk |
Oppretter NAV-identer i NIK over Rest |
|
NØF - NAV Økonomiske fullmakter |
Arbeidstid |
Ikke kritisk |
TODO |
TODO |
Avvikssystemet |
Arbeidstid |
Ikke kritisk |
Henter leder og orgHierarki via graphQL |
|
Oppgavestatistikk? |
Arbeidstid |
? |
Henter alle ressurser en leder er leder for |
- |
Oppgave/Modia? |
Arbeidstid |
Ikke kritisk |
Henter navn på ressurser |
- |
8.2. NOM konsumerer følgende løsninger
I listen under har vi ikke listet opp rent tekniske avhengigheter til f.eks. sikkerhetsløsninger. Kun funksjonelle avhengigheter knyttet til dataflyt er listet opp. .NOM konsumerer følgende
| Produsent | Konsumerer hva | Konsekvens av nedetid | Evt. kommentar |
|---|---|---|---|
DVH |
all data om ressurs og orgEnhet |
Data i NOM utdatert på 24t |
|
Unit4 |
sender ressursinfo ifm. endringer |
Stopp i opprett/endre-ressurs prosess. Lagres lokalt i NOM, men får ikke fullført mot Unit4. Mer manuelt arbeid. |
TODO |
AD |
Profilbilder |
Får ikke vist profilbilder. NOM UI fungerer ellers. |
|
Telenor |
Telefonnr for interne |
TODO. Har vi lokal kopi? |
TODO |
9. Tipcs & Tricks
-
Se .tools for diverse verktøy.
-
kubectl port-forward: Gjøre kall til tjenester i miljø.kubectl port-forward deployment/[deployment-name, f.eks nom-api] -n nom 8081:8080.
10. Veivalg
10.1. JSON vs Avro på Kafka
10.1.1. JSON
Fordeler
-
Alle kan det og må kunne det pga det blir brukt flere steder.
-
Stort community, mye dokumentasjon.
Ulemper
-
Ingen schema validering by default, dette kan legges på.
-
Tar mye plass (mye redundant data i forhold til Avro, f.eks field keys).
11. Interne Hendelser
Forslag til intern hendelsesmodell.
11.1. Grunnprinsipper og terminologier
11.1.1. Endringstyper
En hendelseType er den opprinnelige handlingen som ble gjort av en bruker.
Når man snakker om endringstyper og hendelser, så vil alltids endringstyper være i fortid. Dette er fordi hendelsen er et resultat av noe som har skjedd og en logg på dette.
Opprettet
Opprettelse av en ny organisasjonsenhet / ressurs / organisering.
Denne vil ikke få en ID via UI, men blir generert av backend. Validering vil skje på tvers, dvs at man sjekker mot andre organisasjonsenheter om ting går på tvers. Eksempel på dette er hvis man ender opp med å ta inn 4-talls nummer, så kan en valideringsregel være at man ikke kan opprette en organisasjonsenhet med et likt 4-tall som en eksisterende enhet.
Endret
Endre spesifike opplysninger på en enhet.
Her kommer man med en eksisterende ID for organisasjonsenhet og skal endre noen spesifikke felter. Eksempel er at man i dag har Oslo Gamle Byen, men fra 2021-01-01 så skal denne hete: Oslo Gamle Staden. Dvs at det som sto der før 2021-01-01 var korrekt, men vi skal endre noen attributter på enheten som kan slå inn på et gitt tidspunkt.
Korrigert
Det som står der er feil, har aldri vært korrekt.
Her kommer man inn med ID på enheten + gyldig fom og feltene som skal korrigeres. ID + GyldigFom vil være nok informasjon til å entydig identifisere hvilke hendelse det er snakk om, men må byttes ut til den tekniske hendelsesIden på baksiden. Grunnen til dette er fordi man skal peke på en spesifik forekomst til en organisasjonsenhet i tid. Et alternativ til å peke på hendelsesIden ville være å peke på Iden til Enheten + tidspunkt, men det gjør at man ikke kan endre tidspunktet ettersom det da ville være id + tidspunkt som gjør den unik.
2021-01-01
\/
|---- NAV Gamke Byen ---->|---- NAV Gamle Staden ---->
|---- NAV Gamle Byen ---->I dette tilfellet, sier man at NAV Gamke Byen aldri har vært korrekt og skal være NAV Gamle Byen.
Opphørt
Setter gyldig til en dato. Kan diskuteres om trengs. Alternativet er å lage en endring som setter gyldig til.
Annullert
Skulle aldri ha blitt opprettet til å begynne med.
|---- NAV Gamle Byen ---->|---- NAV Gamlk Staden ---->Det skulle aldri ha vært utført en endring på NAV Gamle Byen, så endringen skal annulleres. Da vil man annullere kun den siste og stå igjen med:
|---- NAV Gamle Byen ---->Det samme kan man si om en original opprettelse. F.eks ved at man oppretter en organisasjonsenhet for mye eller en som ikke skulle vært lagd av andre grunner.
11.1.2. Tidslinjer
Tidslinjer blir definert innad en id. F.eks for enhet, så vil en organisasjonsenhet ha en ikke meningsbærende id (UUID) som vil gjelde for den spesifikke enheten i hele livsløpet. Men enheten kan endres over tid.
|---- NAV Gamle Byen ---->|---- NAV Gamle Staden ---->I dette tilfellet, så snakker man om en endring i tid. Dette setter IKKE gyldig til på den forrige. Begrunnelsen for dette er at endringer natulig tar over for endringer med nyere gyldig fra dato. Dette gjør at man slipper å kjøre cascading endringer dersom man skal flytte på gyldig fra.
Dagens dato
\/
|---- NAV Gamle Byen ----||---- NAV Gamle Staden ---->
Satt inn feil dato frem i tid for når NAV Gamle Staden skal ta over.
Nå vil man måtte korrigere på NAV Gamle Byen (gyldig til) og NAV Gamle Staden (gyldig fom).11.2. Tekniske detaljer
En hendelse i NOM er et innslag av en handling fra et system eller en autorisert bruker. Eksempler er opprettelse av enheter, ressurser, o.l.. Alle disse, blir wrappet inn i en felles hendelsesklasse som inneholder metadata om hva som omfattes, hvem som utførte handlingen, når det ble gjort. Merk: Det er forskjell mellom den interne hendelsesmodellen og hva som blir eksponert ut på GraphQL. GraphQL er et view av mange forskjellige hendelser som kan være utført over tid. Eksempelvis, hvis en organisasjonsenhet har blitt opprettet, så korrigert, da vil kun informasjon fra korrigeringen bli presentert (den opprinnelige opprettelsen blir da teknisk historisk).
Bruker NOM-Api Kafka
------Opprett Enhet--------->
Validering
---- I en Transaksjon ---->
<-- Leses inn i In-Mem ----
<-----Response--------------Ett issue med modellen er at forskjellige pods vil potensielt være noe ute av sync i noen ms. Svaret tilbake til bruker/ui kommer fra samme pod, så i hovedsak ikke et problem på den forespørselen, men potensielt hvis man spør flere ganger imellom der. Dette vil være et edge case, men greit å være obs på det.
11.2.1. Utforming av hendelser
Data Access Objects
Unresolved directive in interne-hendelser.adoc - include::../../../../../apps/api/src/main/java/no/nav/nom/apps/api/hendelse/contract/IHendelse.java[tag:class]Unresolved directive in interne-hendelser.adoc - include::../../../../../apps/api/src/main/java/no/nav/nom/apps/api/hendelse/contract/HendelseType.java[tag:class]Unresolved directive in interne-hendelser.adoc - include::../../../../../apps/api/src/main/java/no/nav/nom/apps/api/hendelse/contract/HendelseDataType.java[tag:class]Unresolved directive in interne-hendelser.adoc - include::../../../../../apps/api/src/main/java/no/nav/nom/apps/api/hendelse/contract/HendelseMetadata.java[tag:class]Note:
-
Dropper opprettetAv i hver hendelse, ligger i hendelse om utførelse av operasjonen.
{
"id": "bca0f4ca-5c62-4e0d-a991-78dfb7ce85c1",
"reqId": "0eb9f6bc-f65e-4958-b895-309d511b6a50",
"type": "no.nav.nom:Operasjon:v1",
"hendelseType": null,
"opprettet": "2021-02-03T13:37:00Z",
"data": {
"fid": "0eb9f6bc-f65e-4958-b895-309d511b6a50",
"operasjon": "Enhet:Opprett",
"input": {
"navn": "Oslo Gamle Byen",
"gyldigFom": "2020-01-01"
},
"opprettetAv": "G141145"
}
}{
"id": "39af382a-8ab0-4fbd-9ec1-baeab6ec9ec6",
"reqId": "0eb9f6bc-f65e-4958-b895-309d511b6a50",
"type": "no.nav.nom:Enhet:v1",
"hendelseType": "OPPRETTET",
"opprettet": "2021-02-03T13:37:00Z",
"data": {
"fid": "1edf5b33-a3f1-4388-9200-17fb6ea0a11b",
"navn": "Oslo Gamle Byen",
"gyldigFom": "2020-01-01"
}
}{
"id": "7e586831-6c98-4e5a-a953-fcdc5e0d2359",
"reqId": "417b9f12-f931-45cc-9ab9-ec6131aafe9c",
"type": "no.nav.nom:Operasjon:v1",
"hendelseType": null,
"opprettet": "2021-03-03T13:37:00Z",
"data": {
"fid": "417b9f12-f931-45cc-9ab9-ec6131aafe9c",
"operasjon": "Enhet:Korriger",
"input": {
"navn": "Gamle Oslo"
},
"opprettetAv": "G141145"
}
}{
"id": "b65d953c-c666-4fe7-af47-aaf28a994b2e",
"reqId": "417b9f12-f931-45cc-9ab9-ec6131aafe9c",
"type": "no.nav.nom:Enhet:v1",
"hendelseType": "KORRIGERT",
"opprettet": "2021-03-03T13:37:00Z",
"data": {
"fid": "1edf5b33-a3f1-4388-9200-17fb6ea0a11b",
"navn": "Gamle Oslo"
}
}I GraphQL blir det noe ala:
{
"id": "1edf5b33-a3f1-4388-9200-17fb6ea0a11b",
"navn": "Gamle Oslo",
"gyldigFom": "2020-01-01",
"metadata": {
"endringer": [
{
"hendelseId": "39af382a-8ab0-4fbd-9ec1-baeab6ec9ec6",
"reqId": "0eb9f6bc-f65e-4958-b895-309d511b6a50",
"opprettetAv": "G141145",
"opprettet": "2021-02-03T13:37:00Z",
"hendelseType": "OPPRETTET"
},
{
"hendelseId": "b65d953c-c666-4fe7-af47-aaf28a994b2e",
"reqId": "417b9f12-f931-45cc-9ab9-ec6131aafe9c",
"opprettetAv": "G141145",
"opprettet": "2021-03-03T13:37:00Z",
"hendelseType": "KORRIGERT"
}
]
}
}11.2.2. Kafka
Event Sourcing Topic
Inneholder alle hendelser av alle typer over tid, med endringer. Evig retention og cleanup policy = delete.
Something something Topic
Usikker på navn, i PDL var det persondokument. Inneholder nåværende informasjon om en entitet med et predefinert nivå man skal gå ned i koblet data. F.eks: Ressurs + koblinger + organisasjonsenhet sin id. Samme motsatt vei, Organisasjonsenhet + koblinger + ressursene sine id.
12. Eksterne systemer
12.1. DVH
Format fra datavarehus.
12.1.1. Feed 1: Enhetsinformasjon
Ønsker en changelog.
Note: Hvis det finnes en EK, vil vi gjerne ha dette. Dersom det blir relevant å ta inn enheter fra forskjellige systemer, så ta med dette også (ORG_NODE_TYPE_KODE).
Behovet har vært signalisert at er kun det formelle hierarkiet og dermed også de enhetene som er en del av dette? Virtuelle arbeidskøer holdes utenfor.
| Attributt | Prioritet | Eksempel | Beskrivelse |
|---|---|---|---|
Sekvens |
Change log sekvens |
||
DvhId |
Høy |
EK? EK kan være et nummer eller tekst, avhengig av hva som skal til for å lage en EK |
|
Navn |
Høy |
NAV Oslo - Sagene |
|
LederRessursNr |
Null hvis ikke relevant |
||
NorgId |
Høy |
0301 |
Norg enhets ID. 4er tall, eventuelt med bydel, hva brukes mest? |
AgressoNr |
0301001 |
Null hvis ikke relevant |
|
RemedyNummer |
Null hvis ikke relevant |
||
GyldigFom |
Høy |
Fra og med |
|
GyldigTil |
Høy |
til (ekslusiv) |
|
Opprettet |
Tidspunkt for opprettelse |
||
OpprettetAv |
Hvem som opprettet enheten |
Det kan være flere rader med lik DvhId. Høyeste sekvensnr betegner gjeldende rad for gitt DvhId.
12.1.2. Feed 2: Organisering
Ønsker en changelog.
Behovet har vært signalisert at er kun det formelle hierarkiet.
| Attributt | Prioritet | Eksempel | Beskrivelse |
|---|---|---|---|
Sekvens |
Change log sekvens |
||
DvhStukturId |
Høy |
EK? EK kan være et nummer eller tekst, avhengig av hva som skal til for å lage en EK |
|
DvhIdOver |
Høy |
EK til Overenhet |
|
DvhIdUnder |
Høy |
EK til Underenhet |
|
GyldigFra |
Høy |
||
GyldigTil |
Høy |
||
Opprettet |
Tidspunkt for opprettelse |
||
OpprettetAv |
Hvem som opprettet organiseringen |