Synt Meldekort
Overordnet arkitektur
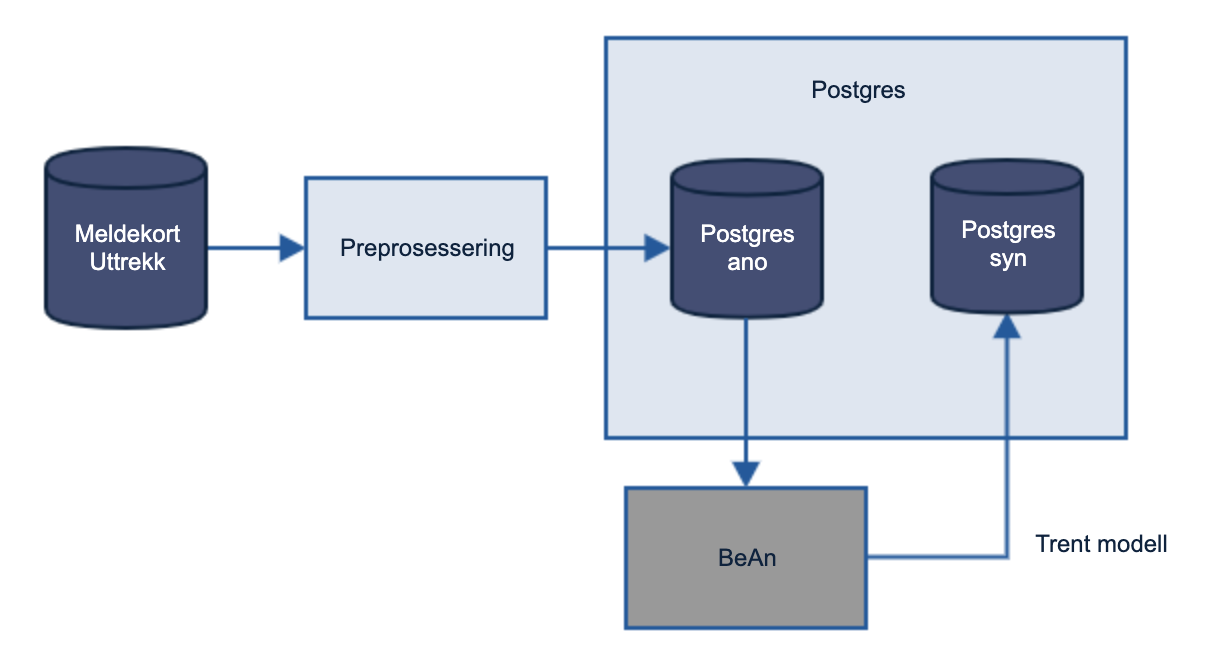
Beskrivelse
I forrige versjon av meldekort, benyttet vi en alternativ syntetiseringsmodell, og gjorde formatering av dataen, anonymiserte den, og lastet den opp i en postgres-database. Modellen som blir brukt på meldekort er delt opp der det er en modell som genererer SPM delen av meldekortet som er spørsmål en person som fyller ut meldekort må svare på. Grunnen til dette er at vi setter de resterende feltene basert på verdiene vi fra den andre syntetiske modellen. Feltene som blir syntetisert på SPM er arbeidssoker og forskudd.
For den andre delen av meldekortet som er DAG, lages det en modell per meldegruppe. DAG inneholder relevant informasjon knyttet til meldekort på dagsbasis. I uttrekket vi fikk er det to ulike meldegrupper, DAGP og ATTF. Modellene blir trent på data fra de ulike meldegruppene og kolonnene det blir trent på er arbeidettimersum, kurs, syk og annetfravaer. De resterende verdiene i meldekort dag blir satt i kode for at de syntetiske meldingene skal gi mening. Dette er ting som å sette dager på DAG meldingene fra 1-14, og legge til signatur.
Etter generering av syntetisk data, blir dataen konvertert til et XML-format som gjør det enkelt for Arena å benytte seg av dataen.
Kernel density modellene blir generert ved førstegangs kjøring og lagret.