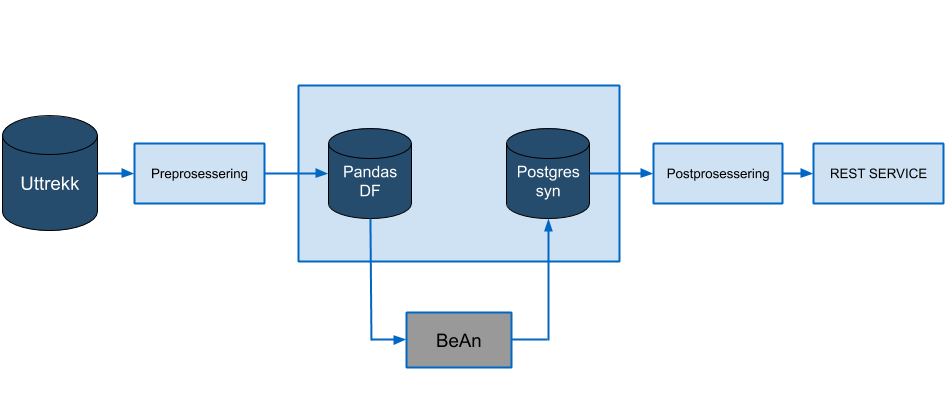
Synt AMelding
Arbeidsforhold
Datagrunnlag
A-melding teamet gjorde i Oktober 2020 et maskert uttrekk med data fra 2018/19.
Hver opplysningspliktig, virksomhet, og ident i uttrekket har blitt byttet ut med en annen tilfeldig, reell ident/orgnr.
Anonymiseringen bar deterministisk så en spesifikk ident/orgnr ble alltid byttes ut med det samme tilfeldige nummeret. Det var ingen reell tilkobling mellom de nye tilfeldig valgte identer/orgnr.
Uttrekket ble også sjekkes for personopplysninger i Team Dolly og alle kolonner med info om opplysningspliktig, virksomhet eller ident ble fjernet før trening av maskinlæringsmodell.
Char-RNN
For å modellere endringene i arbeidsforholdet på en naturlig måte ble det benyttet et char-rnn. Datasettet ble preprosessert, slik at endringene for hver kolonne i en gitt historikk ble enkodet i en 15-bits vektor. Det betyr at en character representerer en endring i meldingen, og bit-verdiene til characteren beskriver hvilke kolonner som skal endres. Kolonnenavnene per posisjon i bit-vektoren er bevart og ble brukt til å senere oversette bit vektorene til de faktiske meldings-feltene.
Datagrunnlag
Fra uttrekket ble det gruppert “historikker” identifisert som grupper av meldinger med samme ident, virksomhetsnummer og arbeidsforholds-id. Disse historikkene ble så sortert basert på rapporteringsmåned. Deretter ble hver endring for hver kolonne enkodet i en bit-posisjon for et binært tall, som så ble enkodet til en char.
Eks.
| idx | Rapproteringsmaaned | Stillingsprosent | Loennsendringsdato | … |
|---|---|---|---|---|
| 0 | 2020-04 | 100 | “12-04-1997” | … |
| 1 | 2020-05 | 100 | “12-04-1997” | … |
| 2 | 2020-06 | 100 | “18-05-2020” | … |
Vil bli enkodet til
0: 1 0 0 ... -> 'a'
1: 1 0 1 ... -> 'b'
Vi ender da opp med en tekststreng av lengde n-1 for en historikk med n meldinger.
Fra uttrekket ble det hentet ut 258 366 unike historikker. Av disse ble det generert 161 647 strenger. (Hvilket betyr at litt under halvparten av “historikkene” bare inneholdt én melding.) Gjennomsnittslengden for arbeidsforholdene var 3.1, med en maks lengde på 22 endringer.
Det ble generert 295 unike chars, som betyr at det finnes 295 unike måter meldingene kan endre seg på. Det ble også laget et seed_dist der en distribusjon av start-chars ble lagret. Dette blir brukt for å initialisere en sekvens.
Samplingsmetoder
Når CRNN modellen predikerer endringer for de forskjellige feltene i arbeidsforholdet, blir det brukt to typer samplingsmetoder for å sette verdiene til de aktuelle feltene.
Postprosessering av permisjoner
Det ble implementert støtte for å holde styr på permisjonsvarighet. Permisjoner som er gyldige beholdes frem til de går ut på dato, eller frem til CRNN modellen og samplingsmetodene bestemmer at neste melding ikke skal ha permisjoner. Permisjoner som ikke har sluttdato varer frem til CRNN modellen og samplingsmetodene bestemmer at neste melding ikke skal ha permisjoner.
Estimering av kjernetetthet
For numeriske og kontinuerlige data ble det laget modeller som tar i bruk en implementasjon av kjernetetthetsestimering (KDE) fra scikit.
KDE modellene for ordinære arbeidsforhold ble trent med et filtrert uttrekk som kun består av meldinger som har en eller flere endringer mellom en rapporteringsmåned og påfølgende måned i uttrekket. For maritime arbeidsforhold benyttes et filtrert uttrekk som kun består av meldinger som har en eller flere endringer, men uten å kreve at rapporteringsmånedene skal være sekvensielle (påfølgende måned er neste måned som er innrapportert, og eventuelle rapporteringsmåneder som mangler for et arbeidsforhold blir ignorert). Disse filtrerte uttrekk vil heretter refereres til henholdsvis som uttrekket med sekvensielle endringsmeldinger, og uttrekket med endringsmeldinger.
Datofeltene ble konvertert til numeriske verdier i preprosesserings-fase. For sluttdato, ble differansen i antall dager mellom sluttdato og startdato lagret. For resten av datofeltene ble differansen beregnet ut i ifra hvordan datoene endrer seg i neste repportering.
For ordinært og maritimt arbeidsforhold ble KDE samplingsmetodene laget for følgende felter:
- SLUTTDATO
- SISTE LOENNSENDRINGSDATO
- SISTE DATO STILLINGSPROSENTENDRING
Kategorisk sampling
For kategoriske data, benyttes det samplingmetoder som lager en oversikt over hvordan verdiene fra uttrekket endrer seg, og deretter bruker denne oversikten til samplingen.
I dette tilfelle brukes uttrekket med sekvensielle endringsmeldinger for ordinære arbeidsforhold, og uttrekket med
endringsmeldinger for maritime arbeidsforhold.
Samplingmetodene returnerer en tilfeldig verdi basert på hvor sannsynlig det er at en verdi endrer seg til andre verdier (for eksempel endrer verdi_1 seg 80% av gangene til verdi_3 og 20% til verdi_2).
Datasettet kan inneholde noen verdier som ikke endrer seg til andre verdier (for eksempel verdi_3 i tabellen har alle verdier satt til 0.0). For å kunne generere endringer på en verdi som er av typen som egentlig ikke endrer seg, brukes generell raden, som returnerer en verdi basert på hvor ofte verdien forekommer i uttrekket.
| verdi_1 | verdi_2 | verdi_3 | rad_sum | |
|---|---|---|---|---|
| verdi_1 | 0.0 | 0.2 | 0.8 | 1.0 |
| verdi_2 | 1.0 | 0.0 | 0.0 | 1.0 |
| verdi_3 | 0.0 | 0.0 | 0.0 | 0.0 |
| generell | 0.5 | 0.2 | 0.3 | 1.0 |
For ordinært arbeidsforhold ble kategorisk samplingsmetodene laget for følgende felter:
- ARBEIDSTIDSORDNING
For maritimt arbeidsforhold ble kategorisk samplingsmetodene laget for følgende felter:
- ARBEIDSTIDSORDNING
- SKIPSREGISTER
- SKIPSTYPE
- FARTSOMRAADE
Noen numeriske data som har begrenset antall verdier ble håndtert på en lik måte som kategoriske data. For disse feltene benyttes samplingmetoder som lager en matrise over alle verdier som endre seg, og deretter bruker denne matrisen til samplingen.
Når det skal samples fra en verdi som ikke eksisterer i endringsmatrisen, blir verdien byttet med den nærmesten verdien i matrisen.
For ordinært arbeidsforhold ble kategorisk samplingsmetodene laget for følgende numeriske felter:
- STILLINGSPROSENT
- ANTALL TIMER PER UKE SOM EN FULL STILLING TILSVARER
- PERMISJON MED FORELDREPENGER
- PERMITTERING
- PERMISJON
- PERMISJON VED MILITAERTJENESTE
- VELFERDSPERMISJON
- UTDANNINGSPERMISJON
For maritimt arbeidsforhold ble kategorisk samplingsmetodene laget for følgende numeriske felter:
- STILLINGSPROSENT
- ANTALL TIMER PER UKE SOM EN FULL STILLING TILSVARER
- PERMISJON MED FORELDREPENGER
- PERMITTERING
- VELFERDSPERMISJON
- UTDANNINGSPERMISJON
Arbeidsforhold - Start
I tillegg til generering av syntetisk arbeidsforhold basert på tidligere arbeidsforhold var det også nødvendig å kunne generere et syntetisk arbeidsforhold for en ident som starter i et arbeidsforhold og har ingen tidligere historikk. For å oppnå dette, ble det brukt generelle samplingsmetoder som ble laget basert på hvilke datafelt som skal genereres og hvilken arbeidsforhold type verdien skal genereres for. Samplingsmetodene genererer en tilfeldig verdi ut i fra hvor sannsynlig verdien forekommer i distribusjonen.
Det ble implementert støtte for generering av start-arbeidsforhold for følgende arbeidsforholdtyper:
- Ordinært arbeidsforhold
- Forenklet oppgjørsordning
- Maritimt arbeidsforhold
For ordinært arbeidsforhold ble samplingsmetodene laget for følgende felter:
- YRKE
- ARBEIDSTIDSORDNING
- STILLINGSPROSENT
- ANTALL TIMER PER UKE SOM EN FULL ARBEIDSFORHOLD TILSVARER
Datofelter for ordinært arbeidsforhold blir satt fra brukerinput bortsett fra sluttdato som forblir tomt.
For forenklet oppgjørsordning ble samplingsmetodene laget for følgende felter:
- YRKE
I uttrekket ble forenklet oppgjørsordning alltid rapportert med startdato, og sluttdato. Derfor ble det laget en todimensjonal KDE model for sampling av startdato og sluttdato samtidig. Datofeltene ble konvertert til numeriske verdier i preprosesserings-fase. For å oppnå dette ble differansen i antall dager mellom rapporteringsmåned og startdato, og rapporteringsmåned, sluttdato lagret.
For maritimt arbeidsforhold ble samplingsmetodene laget for følgende felter:
- YRKE
- ARBEIDSTIDSORDNING
- STILLINGSPROSENT
- ANTALL TIMER PER UKE SOM EN FULL ARBEIDSFORHOLD TILSVARER
- SKIPSTYPE
- SKIPSREGISTER
- FARTSOMRAADE
Datofelter for maritimt arbeidsforhold blir satt fra brukerinput bortsett fra sluttdato som forblir tomt.
Uttrekket med sekvensielle endringsmeldinger ble brukt for ordinære arbeidsforhold, og uttrekket med
endringsmeldinger ble brukt for maritime arbeidsforhold, men i preprosseringen ble all permisjon fjernet. I tillegg ble alle datokolonner for ordinært og maritimt arbeidsforhold fjernet.
Overordnet arkitektur