Synt ELSAM
Syntetisering av ELSAM sykemeldinger
Overordnet arkitektur
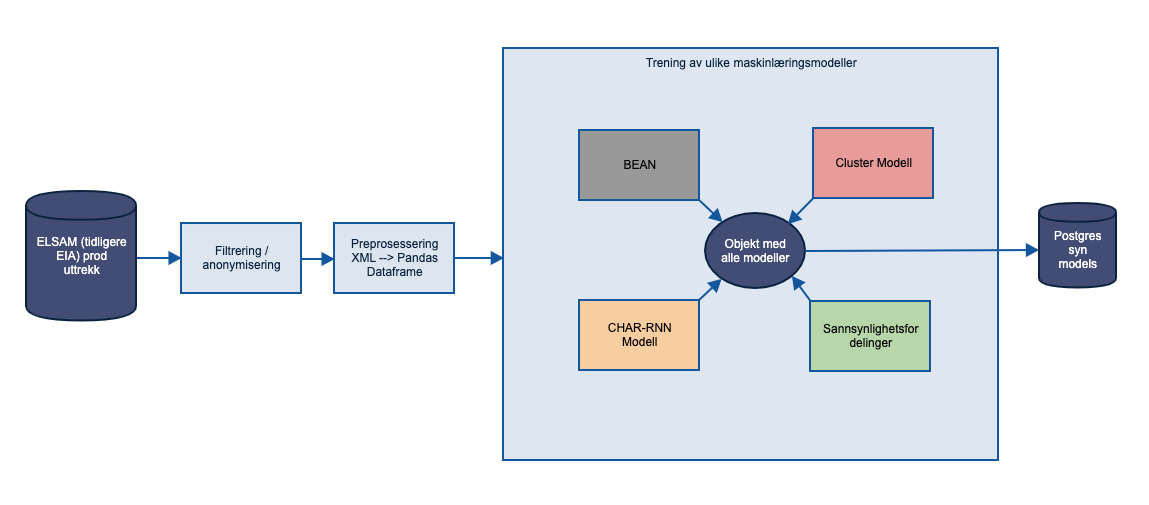 Clustering, Nevrale nett (CHAR-RNN) og sannsynlighetsfordelinger.
Clustering, Nevrale nett (CHAR-RNN) og sannsynlighetsfordelinger.
Datasett
Et uttrekk på ca. 13 000 000 sykemeldinger på XML-format ble først gjort fra en database med ELSAM-meldinger fra prod. Mye av informasjonen funnet i XML-skjemaet er ikke brukt for syntetisering. Denne informasjonen er kritisk for å generere gyldige sykmeldinger og blir lagt til i etterkant for å sikre at dataen ikke er sporbar til enkeltpersoner, samt konsis med syntetiske personer hentet fra vårt syntetiske miljø. Modellene er trent på data knyttet til diagnoser, varighet på sykmeldinger, og endringer i disse.
Arkitekturbeskrivelse
Preprosessering av data
Ved preprosessering av data blir XMLen i string format parset til et tabulært format og anonymisert slik at det ikke ble mulig å identifisere personene med IDer, navn o. l. Deretter ble flere metoder for preprosessering implementert for ulik bruk. I hovedsak ble dataene preprossert på en av følgende måte basert på hvilken modell som var ønsket å trene.
- Gruppert preprosessering
- Ugruppert preprossesering
Gruppert preprosessering ble brukt hvis man var avhengig av sykdomshistorikken til en person. Dette var nødvendig for eksempelvis å trene modeller for å finne relaterte diagnoser, endringer i diagnoser eller endringer i varighet.
Ugruppert preprosessering ble brukt hvis man var avhengig av å vite historikken til en person. Eksempel på dette er trening av BEAN-modellen, som kun skal gi oss èn melding som utgangspunkt for å generere en full sykmeldingshistorikk på en person.
I tillegg til dette ble datane preprossesert forskjellig basert på om det er en gradert eller full sykmelding.
Modeller
CHAR-RNN
CHAR-RNN modellen er et nevralt nett utviklet i PyTorch som ble brukt å generere en streng som representerer endringer i sykmeldingshistorikken over en gitt tidsperiode. CHAR-RNN er et character-based nettverk der man genererer bokstav for bokstav der den neste bokstaven er avhengig av det som er generert foran. For å trene denne modellen trengte man å vite sykmeldingshistorikken til personer slik at man kunne se om det er endringer i diagnose, varighet eller sykmeldingsgrad. For å representere endringer i diagnoser, varighet, eller sykmeldingsgrad har vi to tilstander, 0 = uendret og 1 = endring. Nedenfor er et eksempel på hvordan dette kan se ut på en persons sykemeldingshistorikk:
| Sykemelding # | Diagnose | Varighet | Sykemeldingsgrad | Kommentar |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | Endring i alle felter siden det er første melding. (Blir håndtert med en INIT melding i RNN) |
| 2 | 0 | 0 | 1 | Personen får en endring i sykmeldingsgraden |
| 3 | 1 | 0 | 1 | Personen får endring i både diagnoser og sykmeldingsgrad |
| 4 | 0 | 1 | 0 | Personen får endring i varighet |
Siden CHAR-RNN genererer characters trengte man å representere ulike variasjoner av endringer som enkelt tegn, og det ble da lagd en ordbok som holder styr på hvilken bokstav som mapper til endringer i dataen. Eksempel
| Endringssekvens | Bokstavmapping |
|---|---|
| 111 (INIT) | A |
| 001 | B |
| 101 | C |
| 010 | D |
| 000 | E |
Det ble lagd bokstavmappinger av sykmeldingshistorikken til alle personer slik at det ble mulig å trene en modell for å generere reelle endringer sykmeldingshistorikken til syntetiske personer. Eksempel på en slik streng kan være:
A B B D C E E E E C
For å komme tilbake til hva bokstavene betyr gjør ble det gjort oppslag i ordboken, som gjorde at man kunne mappe tilbake til endringssekvenser å benytte andre modeller til å generere ny diagnose basert på forrige, ny varighet, eller ny sykmeldingsgrad.
Cluster
For å generere clusteret ble det samlet inn alle diagnoser i en sykmeldingshistorikk for en person. Denne dataen ble så brukt til å trene en SciKit Learn Cluster-modell som grupperer relaterte diagnoser. Modellen blir brukt når vi har en endring i diagnose slik at man velger relaterte diagnoser for å generere en så realistisk sykmeldingshistorikk som mulig.
Sannsynlighetsfordelinger
Sannsynlighetsfordelingene er enkle statistiske modeller for å trekke ut nye varigheter på sykmeldinger, bestemme hvor mange sykmeldinger en persons sykmeldingshistorikk skal inkludere, samt fordelingen av sykmeldingsgrader.
BEAN
Formålet med BEAN modellen er å generere syntetisk data tilknyttet innholdet i document-tagen i XML-definisjonen. Denne brukes i hovedsak til å generere dataen i en sykmelding. Hvis vi skal generere en fullstendig sykmeldingshistorikk bruker vi all informasjon fra første meldingen vi får fra BEAN. Ved neste melding benytter vi deler av informasjonen fra BEAN, men bytter ut informasjonen basert på det vi har generert fra de andre modellene for å bevare konsistens gjennom hele sykmeldingshistorikken.
Legeerklæringer
Legerklæringer er syntetisert på samme måte som sykmeldinger med noen få unntak:
- Det er ikke nødvendig å ha historikk på legerklæringer slik at legerklæringer blir syntetisert opp én etter én uten sammenheng.
- Siden vi ikke trenger historikk og sammenheng over en serie legerklæringer, så benytter vi ikke en CHAR-RNN modell for syntetisering av legeerklæringer.