Synt Inntekt
Overordnet arkitektur
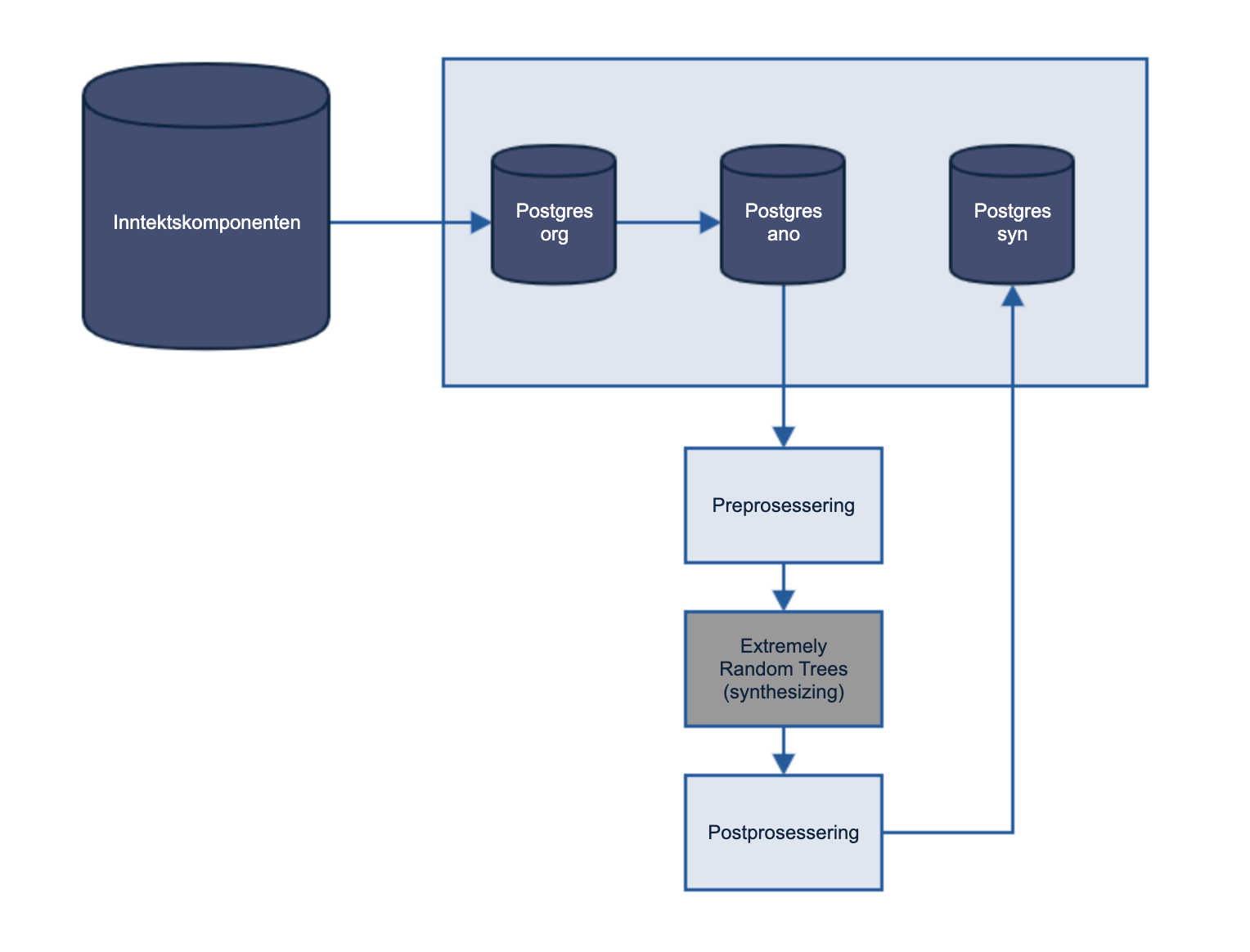
Henting av data
Et utvalg på 1 000 000 inntektsmeldinger ble hentet ut fra inntektskomponenten, anonymisert og lagt inn i en database for mellomlagring. Denne dataen inneholder hovedsakelig tre typer inntekter som er lønnsinntekter, pensjon eller trygd, og ytelse fra offentlig sektor. I tillegg til dette ble det hentet ut et fåtall av næringsinntekter, men pågrunn av svært få slike meldinger, er det nesten ikke generert noen meldinger av denne typen i de syntetiske dataene.
Generering av syntetisk data
Dataen blir først preprosessert der kontinuerlige variabler som beløp forblir på samme format, og diskrete variabler som år og måned blir one-hot-encoded. One-hot-encoding skal i utgangspunktet være unødvendig for kategoriske verdier man sender videre til decision trees (se neste par.), men fordi implementasjonen av decision trees i scikit-learn biblioteket som er tatt i bruk kun opererer med binære splitter og numeriske verdier, måtte disse feltene likevel konverteres. Et eksempel på input til nettet etter preprosessering kan se slik ut:
| AAR_2015 | AAR_2016 | MAANED_1 | MAANED_2 | … | INNTEKTS_TYPE_PENSJONELLERTRYGD | INNTEKTS_TYPE_YTELSEFRAOFFENTLIG | INNTEKTS_TYPE_LOENNSINNTEKTER |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 15300.00 | 3400.00 | 0.00 |
Etter at dataen er preprosessert blir syntetisk data generert ved først å sample ulike inntektsmeldinger fra en kernel density estimation (KDE) over beløp av alle meldingstyper fra samme start-måned. En samling av 300 ulike decision tree regressors blir trent på dataene beskrevet under ‘Henting av data’, og brukes for å generere resten av meldingene sekvensielt. Hver enkelt prediksjon blir utført av et tilfeldig valgt decision tree fra denne samlingen.
En spesiell form for decision tree regressors er tatt i bruk, kalt extremely randomized trees http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.65.7485&rep=rep1&type=pdf. Denne algoritmen er tatt i bruk for å sikre spredning i de syntetiske dataene, ved at alle decision trees ender opp ganske ulike, pga. de tilfeldige splittene i algoritmen. Ved å trene opp mange nok trær blir likevel de statistiske egenskapene til de originale dataen ivaretatt. 300 av disse tilfeldige trær ble tatt i bruk i denne implementasjonen.
Postprosesseringen av data tar de genererte dataene på formatetet forklart over, og gjør det om til et format som adapteret til inntektspakken kan behandle å sende inn igjen til inntektsstub.
Tilgjenglighet av data
Den syntetiske dataen blir lagt inn i Q1 miljøet i inntektstub, og per 07.11.18 er det syntetiske inntektsmeldinger for ca 2700 personer som er tilgjengelig i denne databasen.
Annet
Under utviklingen av syntetiske inntektsmedlinger ble det utprøvd generering ved hjelp av nevrale nett. Ulike nett nevrale nett som Recurrent Neural Networks (LSTM) og Feed Forward Networks ble utviklet og implementert i PyTorch. Datasettet som ble brukt til trening var svært spredt og inkonsistent, noe som gjorde det vanskelig å trene nettverket. Begrenset tilgang på datakraft gjorde det også svært tidkrevende å trene nettverket. Koden for denne implementasjonen finnes på Bitbucket repoet synt_inntekt.