Synt SAM
For syntetisering av SAM ble det benyttet BeAn. SAM data ble hentet ut fra en SAM databasen i Q4, og levert på CSV format. Denne dataen ble så brukt til å trene en modell for å generere syntetisk data. Modellen ble lagret i en postgres database, og blir lastet inn når applikasjonen starter.
Overordnet arkitektur
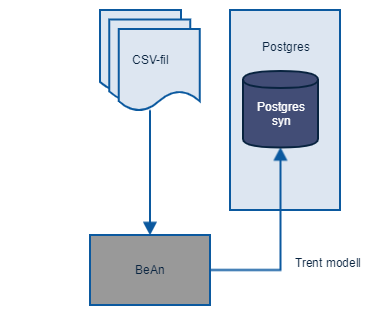
Datagrunnlag
Dataen for syntetisering av SAM ble hentet fra Q4. Det ble hentet data fra tabellene T_SAM_HENDELSE, T_SAM_MELDING, T_SAM_VEDTAK og T_PERSON. Feltene som er brukt til syntetisering er listet nedenfor. Merk at alle kolonnefelter som inneholder IDer er fjernet fra treningsgrunnlaget, da det ikke gir mening å trene på ID-felter som blir brukt til database-logikk.
Kolonner fra databasetabellene:
ANTALL_FORSOK
DATO_ENDRET
DATO_FOM
DATO_OPPRETTET
DATO_PURRET
DATO_SENDT
DATO_SVART
DATO_TOM
ENDRET_AV
ETTERBETALING
K_ART
K_FAGOMRADE
K_KANAL_T
K_MELDING_STATUS
K_SAM_HENDELSE_T
K_TP_ART
K_VEDTAK_STATUS
OPPRETTET_AV
PURRING
REFUSJONSKRAV
VERSJON