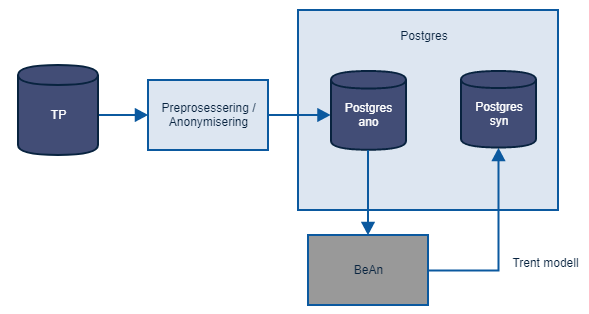
Syntetisering TP
For syntetisering av TP ble BeAn benyttet. Pensjonsopptjeningsdata ble hentet ut fra en TP database som er generert opp ved hjelp av CA-Test Data Manager og knyttet opp mot reelle identer i forbindelse med det nå terminerte maskeringsprosjektet. Dataene er derfor ikke reele og trengte ingen anonymisering. Denne dataen ble så brukt til å trene en modell for å generere syntetisk data. Modellen ble lagret i synt-databasen partert i 6 deler, da denne er for stor til å lagres som ett objekt. Ved innlasting av modellen, blir den satt sammen igjen, slik at den kan brukes til generering av syntetisk data.
Overordnet arkitektur
Datagrunnlag
Dataen for syntetisering av TP er hentet fra Q1. Tabellen det er hentet fra er T_YTELSE og følgende kolonner er brukt:
dato_innm_ytel_fom
k_ytelse_t
k_melding_t
dato_ytel_iver_fom
dato_ytel_iver_tom
dato_opprettet
opprettet_av
dato_endret
endret_av
versjon
er_gyldig
funk_ytelse_id
dato_bruk_fom
dato_bruk_tom